Concurrency Models in Python
/ 13 min read
Introduction
This is part of a series of learning from Fluent Python by Luciano Ramalho.
Recently, my core focus has been on performance testing our proxy server for accessing LLMs in preparation for production within our internal infrastructure. The term concurrent users frequently comes up when exploring performance testing tools such as Locust. While I understand the general concept of concurrency, I had not deep-dive into concurrency in Python. Hence, I decided to start this article to better understand the core concepts and how they apply to Python.
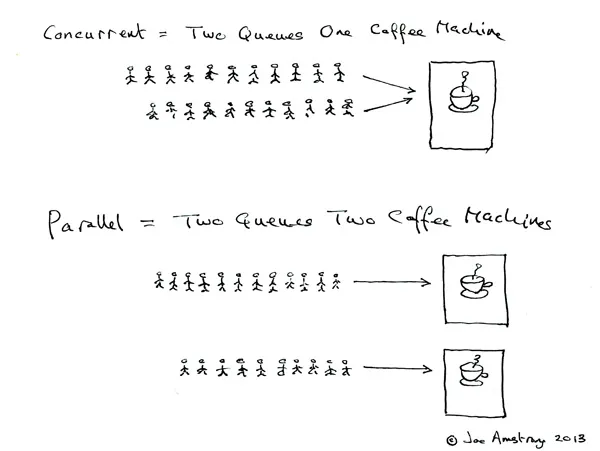
To begin, let’s understand the concept of concurrency vs. parallelism as explained by Rob Pike (in the context of Go, but still relevant for Python to an extent):
For some, understanding concurrency vs. parallelism can be challenging, as they’re often used interchangeably. The following provides a clear distinction between the two:
Concurrency: Ability to handle multiple pending tasks, making progress one at a time or in parallel so that each of them eventually succeeds or fails.
Parallelism: Ability to execute multiple tasks at the same time. This requires multicore CPU, multiple CPUs, or GPU.
With that understanding, let’s dive into why concurrency in Python is often viewed as problematic, especially regarding its multithreading performance.
Issue with The Infamous GIL
Python’s Global Interpreter Lock (GIL) is a mutex, prevents multiple threads from executing Python bytecodes at once to ensure thread safety.
Thread: An execution unit within a single process, sharing the same memory space with other threads, which can risk corruption if multiple threads update the same object concurrently. Threads consume fewer resources than processes for the same tasks.
The main issue with the GIL is that it creates a performance bottleneck, limiting the parallelism of CPU-bound Python programs because only one thread can execute Python code at a time.
For example, let’s compute the Fibonacci numbers using 4 threads versus sequentially for 4 iterations:
#!/usr/bin/python# -*- coding: utf-8 -*-import threadingimport timefrom functools import wraps
def timeit(func): @wraps(func) def timeit_wrapper(*args, **kwargs): start_time = time.perf_counter() result = func(*args, **kwargs) end_time = time.perf_counter() total_time = end_time - start_time print(f"Time taken: {total_time:.4f} seconds") return result return timeit_wrapper
def fibonacci(n: int): if n <= 1: return n return fibonacci(n-1) + fibonacci(n-2)
def compute_fibonacci(): for i in range(35, 40): print(f"Fibonacci({i}) = {fibonacci(i)}")
@timeitdef multithreaded_fibonacci(num_threads: int ): threads = []
for _ in range(num_threads): t = threading.Thread(target=compute_fibonacci) threads.append(t) t.start()
for t in threads: t.join()
@timeitdef sequential_fibonacci(num_iterations: int): for _ in range(num_iterations): compute_fibonacci()The assumption is that with modern multi-core CPUs, running on 4 threads should provide an improvement over running sequentially for 4 iterations.
However, the results shows otherwise:
if __name__ == "__main__": multithreaded_fibonacci(4) sequential_fibonacci(4)
>>> Time taken: 107.7314 seconds>>> Time taken: 106.4314 secondsAs GIL prevents other threads from executing Python bytecode concurrently, multi-threaded performance was similar to single-threaded performance, and actually slower due to the overhead of context switching between threads.
Multi-threading to Multi-processing
If concurrency with multiple threads gives you trouble, let multiple processes set you free.
Given the dismal performance of multi-threading in CPU-bound tasks, it makes sense to use multiprocessing or concurrent.futures.ProcessPoolExecutor to leverage processes and execute tasks concurrently across multiple cores, despite the higher computational cost.
For example, if we were to repeat the setup using multiprocessing and run the task across 4 processes instead:
import multiprocessing
@timeitdef multiprocess_fibonacci(num_processes: int): processes = []
for _ in range(num_processes): p = multiprocessing.Process(target=compute_fibonacci) processes.append(p) p.start()
for p in processes: p.join()
if __name__ == "__main__": multiprocess_fibonacci(4)
>>> Time taken: 27.6426 secondsWe noticed that the time taken is now one-fourth of the time required in either single-threaded or multi-threaded execution.
Processes are still preferable for CPU-bound tasks that require true parallelism, despite the complexity of communication between processes due to their isolated memory.
While the example above demonstrates how we can use multiple processes to speed up a task, one issue not highlighted is that when we delegate tasks to separate threads or processes, we do not explicitly call the function directly, and thus, we are unable to return values from the tasks.
However, with multiprocessing, we can use queues to store results from tasks completed by different processes and then retrieve those values in the main process that delegated the tasks.
An example would be coordinating multiple processes to perform 20 prime number checks:
#!/usr/bin/python# -*- coding: utf-8 -*-import multiprocessingimport randomimport timefrom dataclasses import dataclassfrom multiprocessing import queues
# will take some timeNUMBERS = [i for i in range(100_000_000)]
@dataclassclass PrimeResult: n: int prime: bool elapsed: float
JobQueue = queues.SimpleQueue[int]ResultQueue = queues.SimpleQueue[PrimeResult]
def is_prime(x): if x < 2: return False else: for n in range(2,x): if x % n == 0: return False return True
def check(n: int) -> PrimeResult: t0 = time.perf_counter() res = is_prime(n) return PrimeResult(n, res, time.perf_counter() - t0)
def worker(jobs: JobQueue, results: ResultQueue): while n := jobs.get(): results.put(check(n)) results.put(PrimeResult(0, False, 0.0))
def start_jobs(procs: int, jobs: JobQueue, results: ResultQueue): for _ in range(20): r = random.randint(0, 100_000_000 - 1) jobs.put(NUMBERS[r])
for _ in range(procs): proc = multiprocessing.Process(target=worker, args=(jobs, results)) proc.start()
# add poison pills after starting all processes for _ in range(procs): jobs.put(0)
def report(procs: int, results: ResultQueue) -> int: checked = 0 procs_done = 0 while procs_done < procs: result = results.get() if result.n == 0: procs_done += 1 else: checked += 1 label = "p" if result.prime else " " print(f"{result.n:16} | {label} | {result.elapsed:.9f}") return checked
def main(): procs = multiprocessing.cpu_count()
t0 = time.perf_counter() jobs: JobQueue = multiprocessing.SimpleQueue() results: ResultQueue = multiprocessing.SimpleQueue() start_jobs(procs, jobs, results) checked = report(procs, results) elapsed = time.perf_counter() - t0 print(f"{checked} in {elapsed:.4f} seconds")
if __name__ == "__main__": main()worker: A unit of task that accesses inter-process communication (IPC) mechanisms through the use of queues (one for available jobs and one for completed results).start_jobs: Set the premise for the tasks, including the number of jobs for the process pool and using a poison pill to signal termination.report: Monitor process behavior and track the number of completed jobs.
Without any form of IPC, it is not possible to retrieve results from multiple processes because each process operates within its own isolated memory space.
Concurrency for Network I/O
When dealing with network I/O, concurrency is essential because we don’t want to idly wait for remote servers to send responses. While waiting for a response, the application can perform other tasks to maximize resource utilization.
Unlike CPU-bound tasks, multi-threading remains an appropriate model for handling I/O-bound tasks simultaneously.
For example, let’s attempt to retrieve the flag for each country (if available) from Flag Download:
#!/usr/bin/python# -*- coding: utf-8 -*-import timefrom pathlib import Pathfrom typing import Callable, List
import httpx
BASE_URL = "https://flagdownload.com/wp-content/uploads/Flag_of_{}.svg"DEST_DIR = Path("flags")COUNTRIES = [ "Afghanistan", "Albania", "Algeria", "Andorra", "Angola", "Antigua and Barbuda", "Argentina", "Armenia", "Australia", "Austria", "Azerbaijan", "Bahamas", "Bahrain", ...]
def save_image(image: bytes, filename: str): if DEST_DIR.exists(): (DEST_DIR / filename).write_bytes(image)
def get_flags(name: str) -> bytes: format_name = "_".join(name.split(" ")) url = BASE_URL.format(format_name) resp = httpx.get(url, timeout=5, follow_redirects=True) resp.raise_for_status() return resp.content
def downloader(countries: List[str]): for c in countries: image = get_flags(c) save_image(image, "-".join(c.split(" "))) print(c, end=" ", flush=True) return len(countries)
def main(downloader: Callable[[List[str]], int]): DEST_DIR.mkdir(exist_ok=True) t0 = time.perf_counter() count = downloader(COUNTRIES) elapsed = time.perf_counter() - t0 print(f"\n{count} downloaded in {elapsed:.2f} seconds")
if __name__ == "__main__": main(downloader)As you may notice, there’s nothing concurrent about the attempt above; we are simply iterating through a list of countries sequentially and saving the flags to a specified path. Consequently, the overall process takes a significant amount of time, as seen:
>>> 191 downloaded in 191.45 secondsConcurrent Executors
However, life can be easier with concurrent.futures.Executors which encapsulate the pattern of creating multiple independent threads or processes and collecting results via a queue.
If you recall, the concept of queues was demonstrated in the multi-processing example, where a queue is used as an IPC mechanism to gather results from tasks completed by different processes. However, for threads, because they share the same memory space, communication and data sharing are much simpler. Nevertheless, careful management is required to avoid race conditions and ensure thread safety.
Similar to multi-processes, threads can collect results from workers using shared state variables or thread-safe queues.
However, concurrent.futures simplifies this process by providing the ThreadPoolExecutor and ProcessPoolExecutor classes.
These classes manage a pool of worker threads/processes and handle task distribution and result collection automatically, eliminating the need for manual setup and management.
To demonstrate, let’s convert the sequential process of downloading flags to use multiple threads instead:
#!/usr/bin/python# -*- coding: utf-8 -*-from concurrent import futures
def worker(country): image = get_flags(country) save_image(image, "-".join(country.split(" "))) print(country, end=" ", flush=True) return country
def threadpool_downloader(countries: List[str]) -> int: with futures.ThreadPoolExecutor() as executor: res = executor.map(worker, countries) return len(list(res))
def main(downloader: Callable[[List[str]], int]): DEST_DIR.mkdir(exist_ok=True) t0 = time.perf_counter() count = downloader(COUNTRIES) elapsed = time.perf_counter() - t0 print(f"\n{count} downloaded in {elapsed:.2f} seconds")
if __name__ == "__main__": main(threadpool_downloader)- The only changes required are the introduction of a
workerfunction and the use ofThreadPoolExecutorin the downloader function. The rest remains the same as in the sequential example.
By making minimal changes to the existing code, we can submit callables for execution in different threads, resulting in a performance increase:
>>> 191 downloaded in 9.62 secondsSimilarly, with concurrent.futures we can make use of multi-processing easily by using ProcessPoolExecutor instead:
def processpool_downloader(countries: List[str]) -> int: with futures.ProcessPoolExecutor() as executor: res = executor.map(worker, countries) return len(list(res))
if __name__ == "__main__": main(processpool_downloader)You can expect similar results:
>>> 191 downloaded in 10.22 seconds- You may notice that
ProcessPoolExecutoris actually slower compared toThreadPoolExecutordue to the overhead associated with starting and managing processes. This demonstrates the preference forThreadPoolExecutorfor I/O-bound tasks.
The argument max_workers in either ThreadPoolExecutor or ProcessPoolExecutor defaults to None, which is computed as max_workers = min(32, os.cpu_count() + 4).
Understanding Futures
Futures as stated in Fluent Python are core components in concurrent.futures and asyncio.
Simply put, a Future in either library represents a deferred computation that is pending completion.
In the official documentation as per Python 3.12.4, a Future “encapsulates” the asynchronous execution of a callable.
A similar comparison to a Future would be a Promise in JavaScript.
In asyncio, Futures can be found in asyncio.Future.
One key aspect of Future is that it should not be created manually but rather instantiated exclusively by the concurrency framework.
This is because a Future represents a pending task that will eventually be executed, but it needs to be scheduled first — a responsibility of the concurrency framework.
If you think about it, the status of each executed task should be managed by the concurrency framework, and application code should not interfere with changing the state.
As such, we cannot control when the framework changes the state of the Future.
While executor.map handles Futures behind the scenes, we can use executor.submit to demonstrate the creation of a Future:
def threadpool_downloader(countries: List[str]) -> int: tasks: List[futures.Future] = [] completed: int = 0 with futures.ThreadPoolExecutor() as executor: for c in countries: future = executor.submit(worker, country=c) tasks.append(future) print(f"scheduling future: {future}")
for future in futures.as_completed(tasks): res: str = future.result() print(f"Executed future: {res!r}") completed += 1
return completedYou may try to re-run the entire downloading process, and this time you may notice the following outputs:
>>> scheduling future: <Future at 0x102df0700 state=running>>>> scheduling future: <Future at 0x102df0a90 state=running>>>> scheduling future: <Future at 0x102f0f370 state=running>...
>>> Executed future: 'Armenia'>>> Executed future: 'Barbados'>>> Executed future: 'Bangladesh'...
>>> 191 downloaded in 5.24 secondsBased on our print statements, we understand that each call to executor.submit returns a Future object.
Unlike executor.map, using executor.submit requires an additional for loop to explicitly retrieve the eventual results.
One further point to note about Future — calling its result method actually blocks the caller’s thread if the result is not ready.
However, with concurrent.futures.as_completed, it does not block the thread as it is an iterator that yields each future as it completes.
Ease vs Flexibility
While executor.map is easy to use and produces the same results as using both executor.submit with concurrent.futures.as_completed, it is less flexible in dealing with different callables and arguments.
executor.map is designed to run the same callable on different inputs to the same set of arguments. In contrast, executor.submit allows you to run different callables with different sets of arguments if needed.
To better illustrate the differences between executor.submit and executor.map, let’s consider how each method works:
#!/usr/bin/python# -*- coding: utf-8 -*-from concurrent import futures
def add(a: int, b: int) -> int: return a + b
def square(a: int) -> int: return a * a
def executor_map(): print("\nFutures from executor.map") with futures.ThreadPoolExecutor() as executor: # we cannot run `add` in the same threadpool res = executor.map(square, [i for i in range(100)])
for r in res: print(r)
def executor_submit(): print("\nFutures from executor.submit") tasks = [] with futures.ThreadPoolExecutor() as executor: for i in range(100): add_future = executor.submit(add, a=i, b=i) mul_future = executor.submit(square, a=i) tasks.extend([add_future, mul_future])
for task in futures.as_completed(tasks): print(task.result())
if __name__ == "__main__": executor_map() executor_submit()In general,
submit: Allows you to submit individual callable tasks to the executor. This means you can submit a variety of different tasks, each potentially performing a different function.map: Used to apply the same callable to a collection of arguments, similar to the built-in map function. This is useful when you want to perform the same operation on multiple pieces of data concurrently.
Personally, it’s rather straightforward to opt for executor.map if you are dealing with a single function that you want to run concurrently.
However, if additional logic comes into play under different conditions, then executor.submit would be the better choice.
Conclusion
Concurrency is crucial in modern programming, especially in an era where applications need to be highly accessible and scalable.
In Python, achieving concurrency can be challenging due to the Global Interpreter Lock (GIL), which can limit the performance benefits of multi-threading, particularly for CPU-bound tasks.
In this post, we explored how multi-threading might not always yield the expected performance gains due to the GIL’s limitations, especially for CPU-intensive operations. However, for I/O-bound tasks like downloading data from the internet, multi-threading can be highly effective.
We also discussed how concurrent.futures can simplify handling concurrency by managing queues and result collection for us, making our code more efficient and easier to maintain.
While I am still on the path to mastering concurrency in Python, my learnings from Fluent Python have deepened my understanding of the GIL’s limitations and how to overcome them appropriately, depending on the nature of the tasks.
In the next part of this series, we’ll dive into asynchronous programming, building on our newfound understanding of concurrency. Stay curious and keep learning! 🐍
Many of the code chunks above are adapted from Fluent Python by Luciano Ramalho. I highly recommend you pick up a copy of the book as I find it extremely useful to understand Python on a deeper level.